Optimising ASP.Net MVC web site?
You can use “Yslow” tool for this
Some primary techniques are
1. Remove unused view engines:
E.g. suppose controller action method Home/AAA
The view 'AAA' or its master was not found or no view engine supports the searched locations. The following locations were searched:
~/Views/Home/AAA.aspx
~/Views/Home/AAA.ascx
~/Views/Shared/AAA.aspx
~/Views/Shared/AAA.ascx
~/Views/Home/AAA.cshtml
~/Views/Home/AAA.vbhtml
~/Views/Shared/AAA.cshtml
~/Views/Shared/AAA.vbhtml
By default it will search for both aspx and cshtml view we can remove unwanted view engines by below lines in global.asax file like below
// global.asax
protected void Application_Start()
{
ViewEngines.Engines.Clear();
ViewEngines.Engines.Add(new RazorViewEngine());
}
The view 'AAA' or its master was not found or no view engine supports the searched locations. The following locations were searched:
~/Views/Home/AAA.cshtml
~/Views/Home/AAA.vbhtml
~/Views/Shared/AAA.cshtml
~/Views/Shared/AAA.vbhtml
Note: Thus it will reduces number of loop checks for the view
2. Bundling and minification of JavaScript and CSS:
This will reduces number of HttpRequests to the server also reduces the file size.
3. Remove Duplicate Scripts
4. Use HTTP Compression
You can achieve this by adding setting in web.config file
<system.webServer>
<urlCompression doStaticCompression="true" doDynamicCompression="true" dynamicCompressionBeforeCache="false" />
</system.webServer>
You can typically reduce an HTML document to less than half of its original size. This, in turn, halves the amount of time the client needs to download the page as well as the amount of bandwidth required. All of this is achieved without actually changing the way the site works, its page layout, or the content. The only thing that changes is the way the information is transferred.
Not all files are suitable for compression. For obvious reasons, files that are already compressed such as JPEGs, GIFs, PNGs, movies, and 'bundled content (e.g., Zip, Gzip, and bzip2 files) However, sites that have a lot of plain text content, including the main HTML files, XML, CSS, and RSS, may benefit from the compression
5. Add expiry headers:
So that browser never requests those files again up to expiration time
<system.webServer>
<staticContent>
<clientCache cacheControlMode="UseMaxAge" cacheControlMaxAge="365.00:00:00"/>
</staticContent>
</system.webServer>
6. Optimize Images
7. Use OutputCacheAttribute when appropriate (for frequent data)
[OutputCache(VaryByParam = "none", Duration = 3600)]
public ActionResult Categories()
{
return View(new Categories());
}
8. Put Style sheets at the Top
9. Put Scripts at the Bottom
10. Make JavaScript and CSS External
Good example.
<link rel="stylesheet" type="text/css" media="screen" href="/css/common.css" />
<script type="text/javascript" src="/js/common.js"></script>
Bad example
<style type="text/css">
...
</style>
<script type="text/javascript">
...
</script>
If you include the code and styles inline, they must be downloaded per request.
What is an application pool in IIS?
Application pools allow you to isolate your applications from one another, even if they are running on the same server. This way, if there is an error in one app, it won't take down other applications. Additionally, applications pools allow you to separate different apps which require different levels of security.
Application pools are used to separate sets of IIS worker processes. It is used to isolate our web application for security, reliability, availability and performance and keep running without impacting each other.
One application pool can have multiple worker processes also.
How to separate positive and negative numbers from column?
We have a table with ID column containing following values in it

And the Output should be

And the Output should be
ANS:
SELECT T1.POSITIVE_VALUE, T2.negetive_value
FROM (select id positive_value, ROW_NUMBER() OVER (ORDER BY ID) AS C1 FROM nos WHERE id >= 0) T1
FULL OUTER JOIN (SELECT id negetive_value, ROW_NUMBER() OVER (ORDER BY ID) AS C2 FROM nos WHERE id < 0) T2
ON (T1.C1 = T2.C2)
Write the SQL script to delete/Truncate data from all the tables of the specific database
Recently, I came across this question where candidate had to write a query to empty all the tables from the specific database. Prima facie it feels like a cakewalk for the candidate but believe me it's not. Why not ? Because one must consider the relationships between the tables while writing the query for this question. It could be multilevel hierarchy that one needs to identify before even thinking about deleting the data from the child tables.
So the question gets divided into 2 parts
Identify the relationship hierarchy
Start deleting the data from the bottom i.e from child tables to the parent tables
Now the real question, is it really necessary to identify the hierarchy between tables ? Isn't there any other way to perform this ?
Well there might be many but the one that appealed me is the following one
Disable all the constraints for all the tables
Delete data from all the tables
Enable all the constraints that were disabled in the first step
Following statement can be used to disable all the constraints for a particular table
ALTER TABLE [table name]
NOCHECK CONSTRAINT ALL
And to enable all the constrains
ALTER TABLE [Table Name]
CHECK CONSTRAINT ALL
So the question gets divided into 2 parts
Identify the relationship hierarchy
Start deleting the data from the bottom i.e from child tables to the parent tables
Now the real question, is it really necessary to identify the hierarchy between tables ? Isn't there any other way to perform this ?
Well there might be many but the one that appealed me is the following one
Disable all the constraints for all the tables
Delete data from all the tables
Enable all the constraints that were disabled in the first step
Following statement can be used to disable all the constraints for a particular table
ALTER TABLE [table name]
NOCHECK CONSTRAINT ALL
And to enable all the constrains
ALTER TABLE [Table Name]
CHECK CONSTRAINT ALL
How to get the count of rows for each table of the particular database ?
This is simple yet important question which may feature when someone is interviewing for SQL developer position.
The question goes like this
"How to get the count of rows for each table of the particular database ? How many ways you can think of to fetch the details ?"
Again second part of the question made it interesting because now interviewer wants to understand your knowledge about different ways of Looping in SQL server ?
One obvious answer for this question would be using CURSOR but I'll leave that to you to write instead I'll try to use in-build looping mechanism that comes handy in this situation.
Using SP_MsforeachTable :
sp_msforeachtable - It is in-built procedure which provides cursor like functionality. The SQL code enclosed within this procedure will execute for each table from the database.
As you can see in the screenshot below
In the TEST database, I have 3 tables namely T1 (968 rows), T2 (123 rows) and T3 (123 rows).

Now, I'll try to run the following query
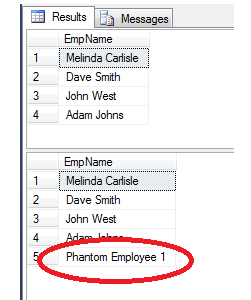
EXEC TestCount..sp_MSforeachtable ' SELECT COUNT(1) As RecCount FROM ? '
As you would have noticed I have used " ? " (question mark) instead of table name in the SELECT statement. Internally sp_msforeachtable replaces this "?" by the table name one by one and executes the SELECT statement.
I received following result. In it each row represents the count of rows from some table but we don't know which row belongs to which table

Hence we must tweak the query to display table name as well. And as I mentioned before " ? " represents the table name here so its just the matter of using it appropriately
EXEC TestCount..sp_MSforeachtable ' SELECT ''?'' as TableName,COUNT(1) As RecCount FROM ? '
The question goes like this
"How to get the count of rows for each table of the particular database ? How many ways you can think of to fetch the details ?"
Again second part of the question made it interesting because now interviewer wants to understand your knowledge about different ways of Looping in SQL server ?
One obvious answer for this question would be using CURSOR but I'll leave that to you to write instead I'll try to use in-build looping mechanism that comes handy in this situation.
Using SP_MsforeachTable :
sp_msforeachtable - It is in-built procedure which provides cursor like functionality. The SQL code enclosed within this procedure will execute for each table from the database.
As you can see in the screenshot below
In the TEST database, I have 3 tables namely T1 (968 rows), T2 (123 rows) and T3 (123 rows).
Now, I'll try to run the following query
EXEC TestCount..sp_MSforeachtable ' SELECT COUNT(1) As RecCount FROM ? '
As you would have noticed I have used " ? " (question mark) instead of table name in the SELECT statement. Internally sp_msforeachtable replaces this "?" by the table name one by one and executes the SELECT statement.
I received following result. In it each row represents the count of rows from some table but we don't know which row belongs to which table
Hence we must tweak the query to display table name as well. And as I mentioned before " ? " represents the table name here so its just the matter of using it appropriately
EXEC TestCount..sp_MSforeachtable ' SELECT ''?'' as TableName,COUNT(1) As RecCount FROM ? '
And this gives us the following result

There is one procedure (sp_spaceused) which gives the complete storage related information about the object.
There is one procedure (sp_spaceused) which gives the complete storage related information about the object.
Let us write one more query with sp_msforeachtable to get the detailed information then
EXEC sp_MSforeachtable ' exec sp_spaceused ''?'' '
and it produces the following output

Using While Loop :
DECLARE @TAB TABLE
(
ID INT IDENTITY(1,1),
TABNAME VARCHAR(1000)
)
INSERT INTO @TAB (TABNAME)
SELECT name FROM SYS.tables
DECLARE @LOOP INT = 1,
@MAXCNT INT,
@NAME VARCHAR(1000),
@QUERY VARCHAR(4000)
SELECT @MAXCNT = MAX(ID) FROM @TAB
WHILE @LOOP <= @MAXCNT
BEGIN
SELECT @NAME = TABNAME FROM @TAB WHERE ID = @LOOP
SET @QUERY = ' SELECT '''+ @NAME + ''' AS TABNAME, COUNT(1) AS CNT FROM ' + @NAME
--PRINT @QUERY
EXEC (@QUERY)
EXEC sp_MSforeachtable ' exec sp_spaceused ''?'' '
and it produces the following output
Using While Loop :
DECLARE @TAB TABLE
(
ID INT IDENTITY(1,1),
TABNAME VARCHAR(1000)
)
INSERT INTO @TAB (TABNAME)
SELECT name FROM SYS.tables
DECLARE @LOOP INT = 1,
@MAXCNT INT,
@NAME VARCHAR(1000),
@QUERY VARCHAR(4000)
SELECT @MAXCNT = MAX(ID) FROM @TAB
WHILE @LOOP <= @MAXCNT
BEGIN
SELECT @NAME = TABNAME FROM @TAB WHERE ID = @LOOP
SET @QUERY = ' SELECT '''+ @NAME + ''' AS TABNAME, COUNT(1) AS CNT FROM ' + @NAME
--PRINT @QUERY
EXEC (@QUERY)
SET @LOOP = @LOOP + 1
END
To summarize at this moment I can think of 3 ways to get the required information
sp_MSforeachtable
While Loop
Cursor
END
To summarize at this moment I can think of 3 ways to get the required information
sp_MSforeachtable
While Loop
Cursor
How to generate values from 1 to 1000 without using WHILE loop and Cursor ? and Using single SELECT or block of code?
;WITH CTE AS
(
SELECT 1 AS NUM
UNION ALL
SELECT NUM + 1 FROM CTE
WHERE NUM < 1001
)
SELECT * FROM CTE
OPTION (MAXRECURSION 1000)
(
SELECT 1 AS NUM
UNION ALL
SELECT NUM + 1 FROM CTE
WHERE NUM < 1001
)
SELECT * FROM CTE
OPTION (MAXRECURSION 1000)
What is the difference between Table Variable and Temp Table ?

Can we have 2 tables with same name in a SQL database ?
Yes, Tables with same name can exists in the same database provided that database has case sensitive collation set on it.
ALTER DATABASE TestCollation
COLLATE SQL_Latin1_General_CP1_CS_AS ;
As you might have noticed I have changed CI to CS in the collation which signifies Case Sensitive..
Now let us try to create tables once again
CREATE TABLE Test(ID TINYINT)
CREATE TABLE TEST(ID TINYINT)
COLLATE SQL_Latin1_General_CP1_CS_AS ;
As you might have noticed I have changed CI to CS in the collation which signifies Case Sensitive..
Now let us try to create tables once again
CREATE TABLE Test(ID TINYINT)
CREATE TABLE TEST(ID TINYINT)
How to Find distinct values without using distinct?
DECLARE @TAB TABLE
(
ID TINYINT
)
INSERT INTO @TAB
SELECT 1 AS ID UNION ALL
SELECT 3 UNION ALL
SELECT 45 UNION ALL
SELECT 76 UNION ALL
SELECT 28 UNION ALL
SELECT 45 UNION ALL
SELECT NULL UNION ALL
SELECT NULL UNION ALL
SELECT 1 UNION ALL
SELECT 3
SELECT * FROM @TAB
;WITH CTE AS
(
SELECT ID, ROW_NUMBER() OVER (PARTITION BY ID ORDER BY ID) ROWNUM
FROM @TAB
)
SELECT ID FROM CTE WHERE ROWNUM = 1
SELECT ID FROM @TAB
GROUP BY ID
SELECT ID FROM @TAB
INTERSECT
SELECT ID FROM @TAB
SELECT ID FROM @TAB
EXCEPT
SELECT 100 -- SOME VALUE THAT ISN'T PRESENT IN ID COLUMN
SELECT ID FROM @TAB
UNION
SELECT ID FROM @TAB
Garbage Collector
Garbage Collector is a feature provided by CLR which helps up to clean unused managed objects.
By cleaning those unused managed objects it reclaims the memory.
It only cleans unused managed objects and does not clean unmanaged objects.
It means anything outside the CLR boundary the garbage collector does not know how to clean it.
Note: garbage collector is nothing but it is a background thread which runs continuously and basically checks if there are any unused managed objects clean those objects and reclaim the memory.
Concept of generation 0,1,2 in GC?
Step1: Application stats and assume 5 objects are created, these 5 objects are moved to generation 0 bucket
Step2: Now G.C. comes and checks for unused object in generation 0 bucket. 2 objects are unused so they get free and GC reclaims the memory. And remaining 3 objects are moved into generation 1 bucket.
Step3: Application keeps on running, it creates 2 more fresh objects and assumes that these 2 objects are not in used and then GC frees these objects, reclaim the memory.
Step4: GC then checks for unused objects in generation 1 bucket (already 3 object where there) frees 1 unused object and remaining 2 objects are moved in generation 2 bucket.
IMP: generations are nothing but they define how long an object has been in the memory
generation2 -- long time objects in the memory
generation1 -- less time objects than generation 2 in the memory
generation0 -- fresh objects in memory
GC visits more in generation 0 bucket and thus increases the performances
**************************
what is optimised code in c#
Multiple document.ready
Can we call a function in one document.ready from another -- NO
types of delegates
Javascript prototype
Mvc extention (advantage of mvc)
Authenticate webApi while calling from jquery
How you set default list using linq if list is emply
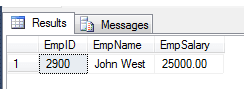
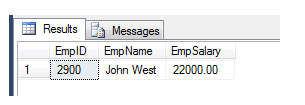
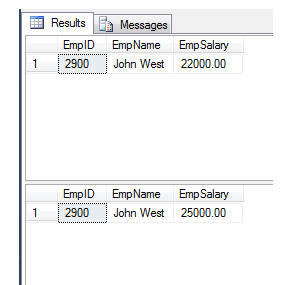
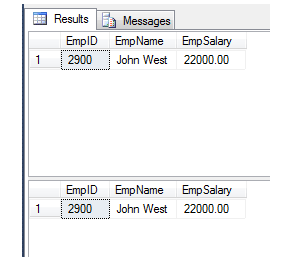
Employee with department - find department wise max salary
asp.net mvc extend controller
**********************
Difference between LINQ to SQL and Entity Framework
LINQ to SQL
Entity Framework
It only works with SQL Server Database.
It can works with various databases like Oracle, DB2, MYSQL, SQL Server etc.
It generates a .dbml to maintain the relation
It generates an .edmx files initially. The relation is maintained using 3 different files .csdl, .msl and .ssdl
It has not support for complex type.
It has support for complex type.
It cannot generate database from model.
It can generate database from model.
It allows only one to one mapping between the entity classes and the relational tables /views.
It allows one-to-one, one-to-many & many-to-many mappings between the Entity classes and the relational tables /views
It allows you to query data using DataContext.
It allows you to query data using EntitySQL, ObjectContext, DbContext.
It provides a tightly coupled approach.
It provides a loosely coupled approach. Since its code first approach allow you to use Dependency Injection pattern which make it loosely coupled .
It can be used for rapid application development only with SQL Server.
It can be used for rapid application development with RDBMS like SQL Server, Oracle, DB2 and MySQL etc.